


Improving Security Data Lake Efficiency with Log Filtering
The problem with unfiltered data, the power of log filtering, practical techniques, and benefits.

SIEMs are among the most expensive security tools a team can buy. As data volumes increase in size and complexity and budgets become tighter, cost strategies have become a necessity.
This post will outline how to optimize SIEM costs with data filtering using common tooling and patterns used today. This approach optimizes security data and enhances the overall management of logging pipelines.
“We need to drastically reduce the amount of logs coming in, however we're struggling to find resources/guides on best practice for event logging” - Inspiration for this post.
How We Got Here
Data might be the new gold, but in audit logging, finding gold requires some mining.
Most logging decisions are binary; logs are ingested into the SIEM or kept at their source, such as a blob storage bucket, an API, or a virtual machine. In the event of an incident, teams must answer questions quickly, and the strategy of non-centralization can be challenging when speed matters, which it always does.
Sending everything to the SIEM is not always an effective or viable strategy from a cost or performance perspective. Logging and retention should be systematic and intentional. If we are collecting something, is it valuable for compliance? Will it help in proactive security monitoring? Hopefully, we maintain high data quality, cost predictability, and sustained value from our data.
The shift to security data lakes has recalibrated our sense of scale. Now that it’s possible to send 10s of Terabytes of logs daily, filtering matters even more. Data lakes and warehouses provide a strong foundation for the next wave of SIEM tooling and AI platforms, but cloud data can still be so big that it’s cost-prohibitive, even going from zero to one. Let’s analyze how to solve that problem.
How to Filter
Starting with a clear intention fosters the best result. In logging, this means asking questions like:
What cost and budget constraints must we stay within?
What logs provide visibility to our threat models?
What evidence must we collect to uphold compliance?
What query performance SLAs should we uphold?
Backing into these answers provides a map for a comprehensive and cost-efficient program. Early in the security team’s maturity cycle, a generic kitchen-sink approach to logging data from clouds, identity providers, and EDR platforms is well-accepted. However, in complex enterprise environments, the number of employees, applications, and hosts are significantly larger, and being choosy about data matters.
Common Patterns
These logs serve as a general reference as being “OK” to drop:
Read-only operations of non-critical assets
Expected internet web traffic to web applications
Network logs between internal hosts or services
DEBUG-level or diagnostic log data from host-based applications
Decrypt API calls
There may be exceptions of what could be dropped, but typically, these logs have little security value. Verbose logs may be valuable to collect somewhere for your development or infrastructure teams, but data retention requirements are typically lower than in SIEM. Because of this, teams often choose a more ephemeral storage location, like Elastic, CloudWatch, or a metrics-focused solution.
Filtering Before The SIEM
There are a few ways to filter data before the SIEM: At the source or in transit. Ideally, this happens as early as possible to avoid sending data that ends up dropped at its final destination.
At The Source
Most security telemetry comes with configuration options, such as the log level, log type, format, and, in the case of IDS-like systems, a set of rules to generate alerts to be forwarded to a centralized location. These settings typically live in configuration management or on the container images themselves.
For utilities like Rsyslog, configuration files determine which data, such as authentication or cron logs, to collect and where to send it. We can reduce overall throughput by choosing specific log or event types to collect. Typically, logs route to a /var/log/ directory on localhost, but they can also be sent over various protocols to log aggregators, eventually making their way to our SIEM.
# Selects all cron messages, except info or debug priority
cron.!info,!debug
# Sends all auth and authpriv logs, regardless of priority
auth.*,authpriv.*From the rsyslog documentation. Syslog-ng has similar and robust filtering functionality.
In AWS, security services like CloudTrail and VPC Flow Logs may be configured similarly.
In CloudTrail, event selectors can set if read, write, or data events are collected from the API, significantly dictating log volume. For use cases where monitoring for exfiltration (TA0010) is important, Data Events from S3 buckets can provide insight into which objects were accessed. In less critical environments, Write events may be the preferred data to collect (over Read) to understand state changes.
When monitoring VPC Flow logs, the desired traffic flows may be expressed upon creation. For example, collecting and analyzing only traffic REJECTed from the VPC could help identify attacks such as external reconnaissance or other nefarious methods of accessing sensitive assets.
aws ec2 create-flow-logs \\
--resource-type NetworkInterface \\
--resource-ids eni-11223344556677889 \\
--traffic-type REJECT \\
--log-group-name my-flow-logs \\
--deliver-logs-permission-arn arn:aws:iam::123456789101:role/publishFlowLogs
Dropping In Transit
Collecting logs from virtual machines or other systems often requires centralization, routing, and transformation pipelines before they reach the SIEM or data lake. This is often done with a logging agent such as Vector, Fluentd, LogStash, or a native SIEM agent. As machines consume logs, data is routed from sources like files on disk or incoming syslog data via TCP. These utilities provide pipeline capabilities and, in most cases, come with filtering options:
<filter cron.critical>
@type grep
regexp1 message cool
</filter>
This Fluentd filter would only allow logs with the string ‘cool’ to pass through to the next step of the pipeline. This approach can also be replicated in the SIEM. This snippet comes from https://docs.fluentd.org/filter.
Filtering In The SIEM
Most SIEMs contain capabilities for filtering events with inclusion or exclusion logic. These can be constructed by first querying the dataset to find high-volume event types that often appear.
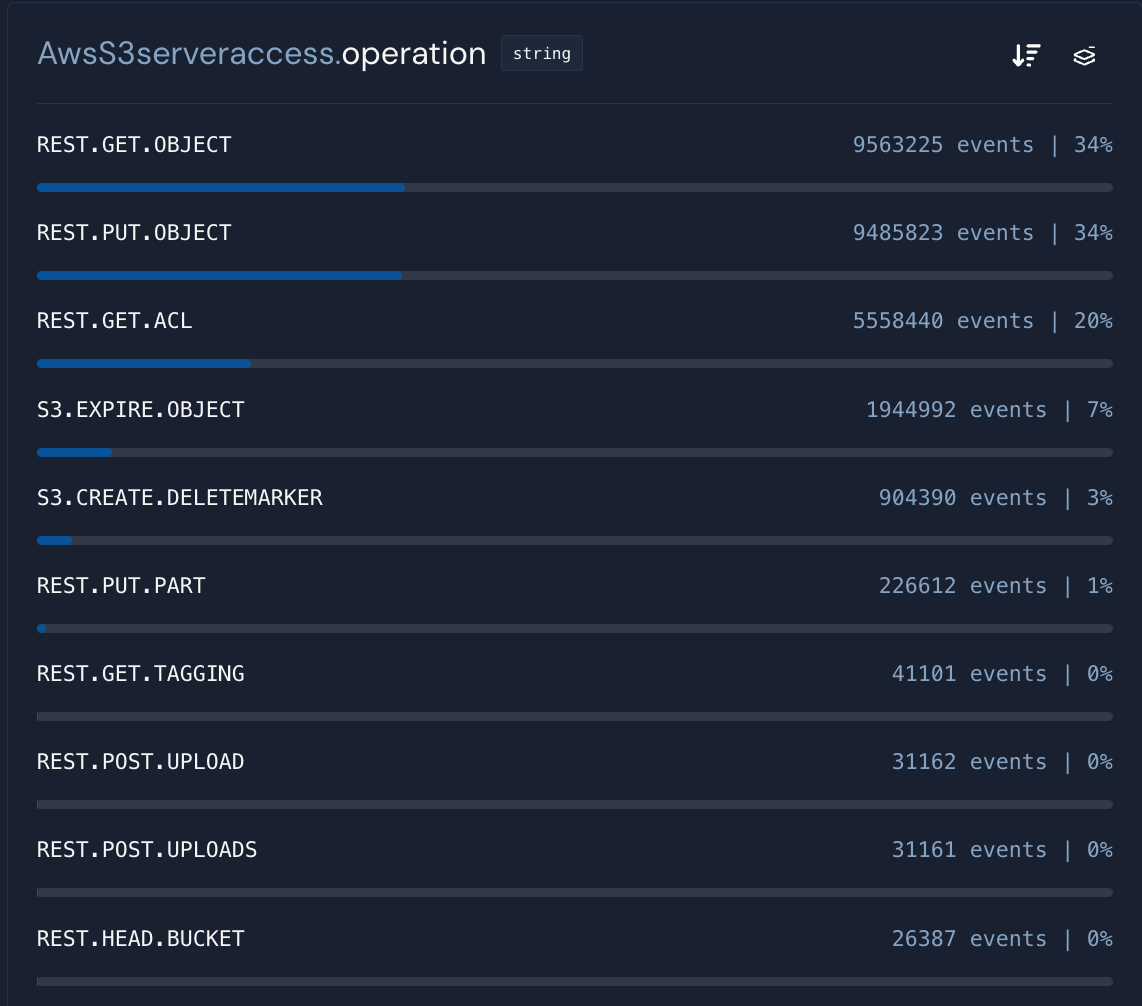
In this AWS S3 Server Access Logs dataset, let’s assume we want to drop REST.GET.ACL data from the internal CloudTrail service. The filter could look like this:
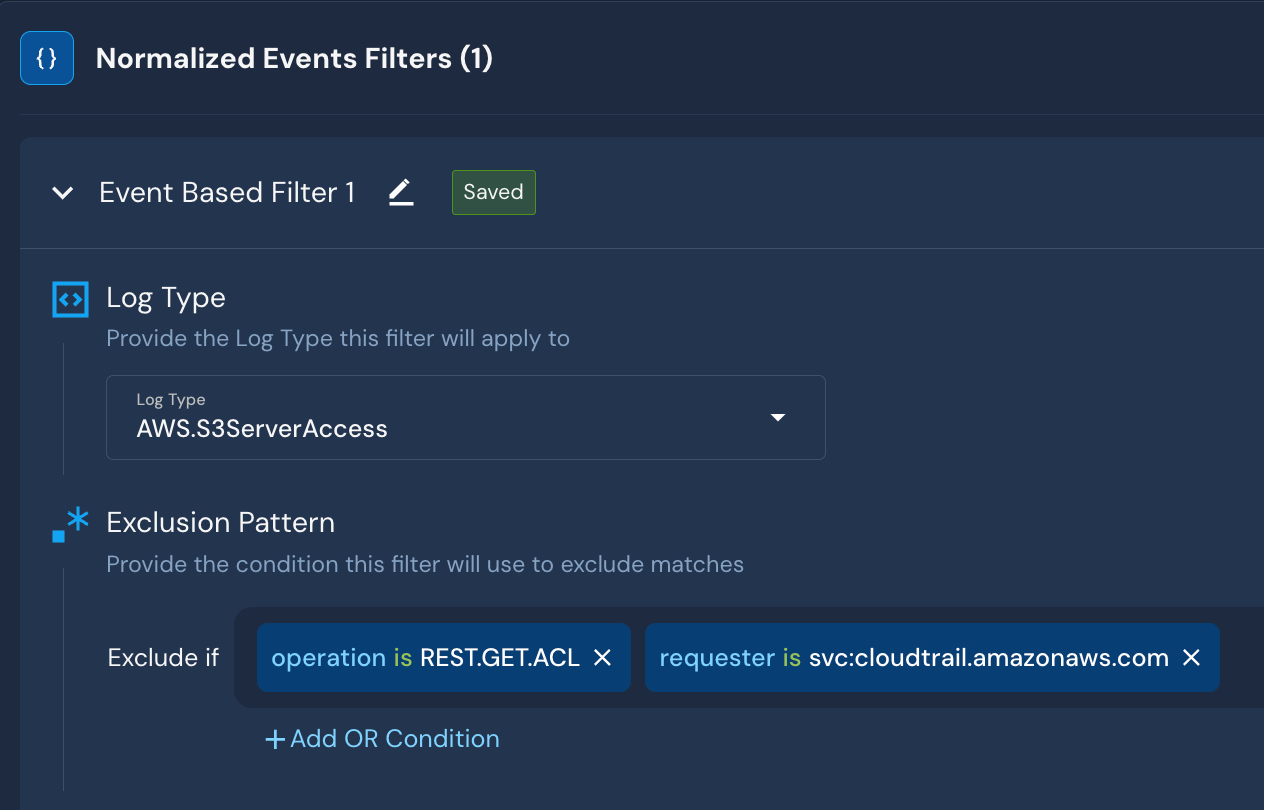
These filters can be repeated across multiple log sources, thus reducing the processing load on queries and rules.
These examples follow Panther’s filtering capabilities.
Benefits of Filtering
Correctness
Logging is unpredictable, and data may not always be able to maintain a well-formed structure. For example, a message field may occasionally be longer than the per-log limit a system can handle, resulting in broken parsing. Filters can check for a common structure before routing or accepting data.
Reduced Storage Costs
Less data means fewer downstream storage costs. The average cost per GB of blob storage across the major cloud providers is around $0.020 per GB, and every new log source adds up.
Data Quality
Dropping security-irrelevant logs can meaningfully improve the overall dataset quality, and we can write simpler queries to find interesting behaviors.
Optimized Performance
With a smaller dataset, queries and rules run much faster, which optimizes our ability to react quicker to incidents and other alerts.
Sustaining Quality
“The objective of cleaning is not just to clean, but to feel happiness living within that environment” - Marie Kondo
In conclusion, security teams can save time and resources by thoughtfully choosing which logs to collect and analyze. They can also improve the quality and relevance of the data they work with, making their efforts more efficient and effective. Remember, every log sent to the SIEM should serve a purpose - whether to meet compliance requirements, aid in threat detection, or provide crucial insights into system performance. By adopting a systematic and intentional approach to log filtering, we can clean our data environment and find happiness and value in living within it.