


Icebergs in the Data Lake
Apache Iceberg could help security teams build scalable data lakes with open storage formats and avoid vendor lock-in.

Welcome to Detection at Scale—a weekly newsletter covering security monitoring, cloud infrastructure, the latest breaches, and more. Enjoy!
Thank you for joining us in 2024. This past year, we reached 1,000 subscribers and are thrilled to continue sharing how to protect organizations at scale!
A growing trend in cybersecurity is building SIEMs with an interoperable data layer backed by cloud storage and a unified schema. This pattern emerged as a reaction to closed SIEM ecosystems where proprietary data formats resulted in lock-in, forcing painful migrations when security teams needed to switch vendors. Apache Iceberg offers a promising solution by providing a neutral, high-scale data layer from which multiple query engines can read. In this post, we'll explore how Iceberg fits into the security data lake and enables teams to build lasting security logging strategies.
What is Apache Iceberg?
Apache Iceberg is an open table format designed for big data analytics in cloud object storage. Originally developed at Netflix, it addresses key challenges in large-scale data management—including reliable concurrent writes, schema evolution, and efficient file management. Iceberg offers several powerful benefits:
Schema evolution for adding, dropping, or renaming fields without rewriting tables
Hidden partitioning that eliminates the need for user-maintained partition columns
Time travel and rollback capabilities to reproduce queries from previous table versions
These features deliver enhanced transactional reliability, performance, and cost efficiency for managing massive data catalogs at scale. The Iceberg specification diagram below illustrates how this metadata layer guides the query engine in locating the correct data.

How Table Formats Play a Role in Searching Data
Table formats are a crucial management layer in data lakes for organizing raw files into structured, queryable tables. Think of it as creating a structured catalog of evidence that investigators can efficiently search through. Iceberg's approach tracks individual data files in tables rather than simple directories, which is how catalogs in AWS Athena operate. This change allows for precise data management where new files can be added in place and committed explicitly, while changes to table structure are handled through atomic operations that maintain consistent views of schema, partitioning, and historical snapshots.
This architecture is particularly valuable for security teams when performing threat hunting queries across vast amounts of historical data. Rather than scanning through endless raw log files or being constrained by traditional SIEM retention limits, analysts can efficiently query specific time ranges and data types powered by Iceberg's metadata layer.
Schema evolution is also particularly important for security logs due to their verbose, unpredictable nature. When logs invariably change, Iceberg can smoothly accommodate new logs while retaining the searchability of old ones. This means faster investigation times and the ability to correlate events across much longer periods - critical capabilities when investigating attackers that may have remained dormant for months.
Developments in the Data Ecosystem
Iceberg is one of today's leading table formats, alongside Delta Lake (from Databricks) and Apache Hudi (from Uber). While these formats share similar scalability and interoperability goals, they each take different approaches to design and favor different query engines.
The original creators of Iceberg went on to found Tabular, a company offering a cloud-native storage engine with managed Iceberg tables. Tabular provided a "BYO-compute" model supporting multiple engines—Spark, Trino, Flink, Athena, BigQuery, and Snowflake—and a hosted data catalog API based on Iceberg. In June 2024, Databricks acquired Tabular to unite Delta and Iceberg:
As one, we are going to lead the way with data compatibility so that you are no longer limited by which lakehouse format your data is in. We intend to work closely with the Iceberg and Delta Lake communities to bring format compatibility to the lakehouse; in the short term inside Delta Lake UniForm and in the long term by evolving toward a single, open, and common standard of interoperability.
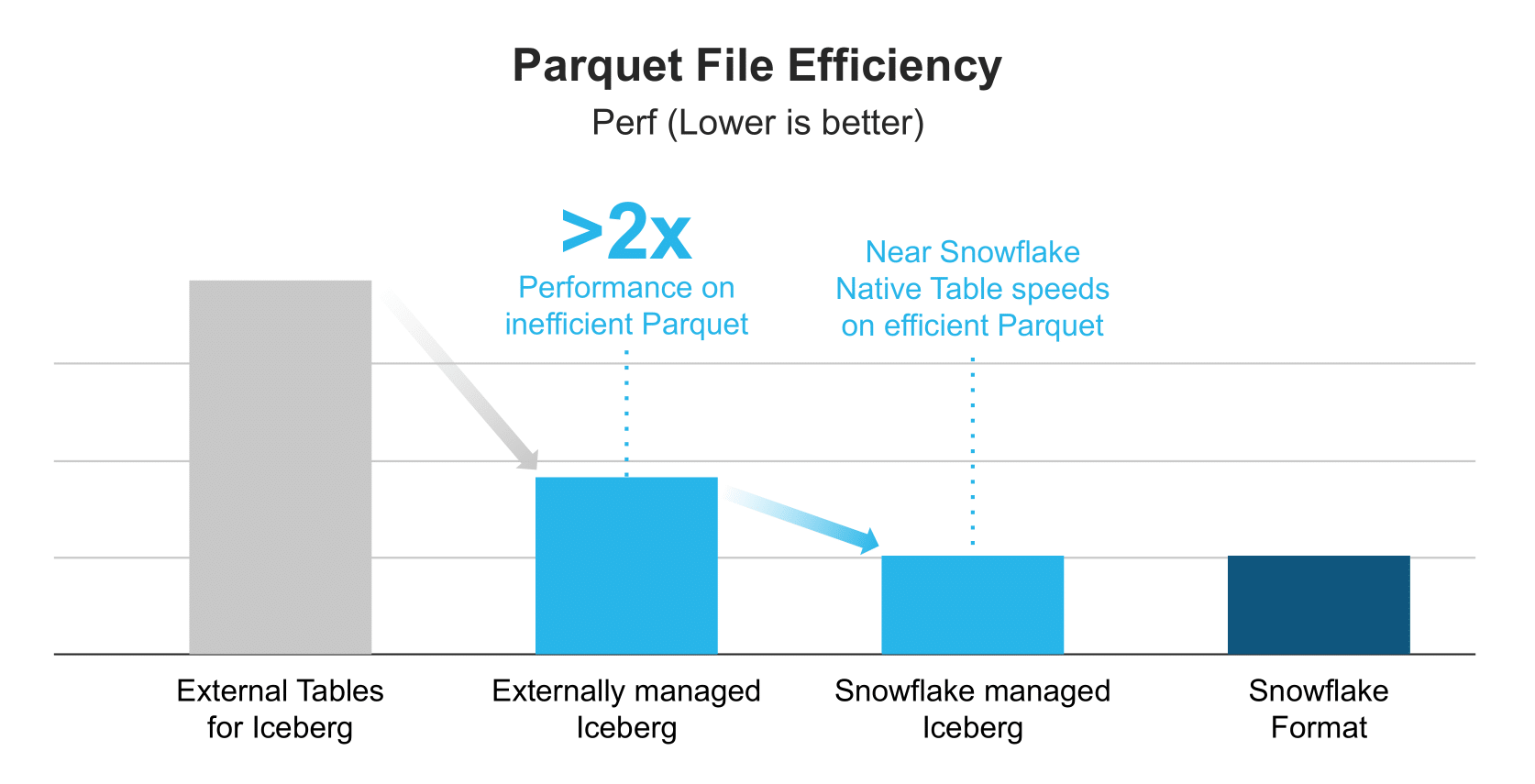
Snowflake, a major competitor to Databricks, also began supporting Iceberg in 2024 as an alternative to its proprietary data format. This support was designed for "existing data lakes that you cannot, or choose not to, store in Snowflake." Like Databricks, Snowflake has worked hard to match Iceberg's performance with its native formats, encouraging adoption while maintaining compatibility with the open standard.
At Re:Invent 2024, Amazon joined the Iceberg movement by integrating it with Amazon S3, the world's most popular storage platform. Their new Amazon S3 Tables feature promises to "streamline tabular data at scale by delivering up to 3x faster query performance and up to 10x higher transactions per second compared to self-managed Iceberg tables." Users can leverage these performance gains while maintaining the flexibility to use their preferred compute engines like Athena, Redshift, Spark, or EMR.
These developments signal the shift towards more open and interoperable data architectures, where organizations can maintain control of their data while benefiting from query performance, scalability, and AI capabilities across multiple platforms. Each platform’s business benefits from increasing its compute spend and will build features to encourage adoption and boost time-to-insights.
Tightly-Coupled SIEMs Are Still Not Built for High-Scale
What does all of this mean for SIEM? Historically, SIEM solutions relied on proprietary database indexes that gave organizations limited control over their data. After companies moved to the cloud in the 2010s, they faced significant operational challenges—SIEM costs soared as data volumes exploded from cloud infrastructure, SaaS applications, and associated auditing needs. The main cost driver is the tightly coupled nature of storage, compute, and indexing. This architecture, combined with proprietary formats incompatible with other platforms and high licensing fees, forces security teams to decide which data to collect and retain.
Major SIEM providers have not yet embraced a comprehensive data lake strategy that could leverage Iceberg's scale and interoperability benefits. While Splunk and Elastic exemplify the traditional approach of proprietary databases and high costs, newer products like CrowdStrike LogScale, SentinelOne's Singularity, and Palo Alto's XSIAM maintain similar architectures— with updated designs. Take Humio (the company behind LogScale) as an example: it uses a tightly coupled storage and compute model, relegating cloud storage to secondary or archival purposes. Though this delivers excellent performance for short-term queries, it falls short for security teams needing to store petabytes of logs across multiple years. Any company ignoring a data lake strategy will struggle to store security logs anywhere beyond six months—a typical retention limit in these products, though we've seen retention periods as short as a few weeks. These systems simply won't be viable for long-term security operations.
How Iceberg Could Disrupt SIEM
Iceberg and similar solutions offer a unified storage layer that security teams can rely on long-term. Organizations embracing this approach tend to favor an open security lake architecture—choosing best-in-breed solutions for specific purposes rather than an all-in-one platform. While future SIEM vendors may need to adapt to a "bring your own compute" (BYOC) model, this shift introduces tradeoffs that could affect core security monitoring needs.
Traditional SIEMs have succeeded by offering comprehensive features: robust content, plugins, integrations, dashboards, and querying capabilities. In a decoupled model—where ingestion/ETL, data storage, and analytics operate independently—security teams need expert infrastructure and data engineers to maintain these complex systems. While this decoupled approach is still commercially unproven, a new "batteries-included" model may prove successful in the long run.
Building an Enduring Security Data Layer
Looking ahead, Apache Iceberg emerges as a compelling solution for organizations seeking scalable, reliable data storage. Its advanced features—schema evolution, hidden partitioning, and rollback capabilities—create the foundation for flexible security infrastructure. While major data warehouse vendors and cloud platforms increasingly adopt Iceberg, traditional SIEM vendors remain committed to their closed ecosystems. Yet, as demands grow for high-scale, long-term cloud auditing, organizations should evaluate how open table formats like Iceberg can support a more sustainable and adaptable security data strategy.
If you enjoyed this post, you may also enjoy reading about the shift to data lakes:
