


The Transition from Monolithic SIEMs to Data Lakes for Security Monitoring
The nuance of data backends to support detection at scale.

This generation of security analytics tools is based on a decoupled data architecture combining cloud storage, open data formats, and highly performant distributed query engines. While this provides improved performance, scalability, and new pricing models for security teams, it comes with a nuance in usability and technical understanding. This blog explores the transition from SIEM to security data lakes, discusses their key components, strategies for interoperability, and query engines for such workloads.
Usability Tradeoffs
The roles of detection engineers and security analysts are distinctly different and mirrored in the technologies that cater to each. Security analysts are often experts in understanding attacker TTPs, and detection engineers specialize in tool accuracy, performance, and capabilities to identify those TTPs. Thus, when responding to incidents, analysts need tools that provide exhaustive answers, and platforms like Splunk and Elastic enabled that by indexing all of the data and coupling it with a simplistic search language. For example, to find all hits on an IP, you could write a basic search like this:
index="dns_logs" "227.86.142.66"While it’s simpler to write these queries over structured or unstructured data, this approach quickly leads to endless query times or exhausting system resources when attempting to search over months or years of data. Introducing data lake architectures provides an alternative, scalable, and more suited approach to log processing but comes with a higher nuance of data engineering concepts. A data lake is effectively a decoupled data warehouse that separates the storage of the underlying data with the processing power to load and query it. Thanks to cloud services, they are becoming increasingly approachable for security teams to run and operate, but have not yet lowered the bar significantly for usability by an analyst. Queries typically are written using SQL, and the same query above could would translate into:
SELECT * FROM dns_logs WHERE dst_endpoint.ip = '227.86.142.66'The advantage of a data lake architecture is that queries can span a much longer timeframe with a higher success rate. The dns_logs table could be gigantic (Petabytes), and with the right data file and format optimizations, this search could also be highly performant.
The disadvantage is that this search only spans a single table, which only includes a subset of your overall dataset. The user running the search must also have an understanding of the data model to understand which fields map to which IoC types. In contrast with the native full-text search approach, this presents some challenges in field sprawl across tables. While there are efforts to make this easier (discussed below in the data modeling section), it still presents a challenge for threat hunting today until all logs are mapped to a single, unified model.
Decoupling the Pipeline
Transitioning from a monolithic SIEM to one backed by a data lake requires a vastly different technology stack. While the originating data sources remain the same on endpoints or servers, the nature to which they are transformed, loaded, and queried is very different.
With the traditional monolithic search platforms, teams simply feed logs into native ingestion mechanism (Splunk’s heavy forwarder and Elastic’s Logstash), and the system indexes it for search. In data lakes, these pieces are more decoupled and becoming more interopable:
Data Routing: Ingestion pipelines to pull/push security logs and events from disparate sources into the data lake using a variety of protocols.
Transformation: Through ETL (Extract, Transform, Load) processes, security data is cleansed and reformatted to maintain consistency.
Storage: Utilize durable storage solutions to retain vast volumes of security data, ensuring scalability and data integrity.
Query Engine: Implement tools like Trino for querying capabilities that identify threats and anomalies.
Metadata: Cataloging systems annotate and classify security data within the data lake to enhance queries.
Real-time Analysis: Stream processing frameworks like Kafka or Spark for on-the-fly security data analysis.
Occasionally, the components above are bundled together. For example, platforms like Databricks and Snowflake support both stream processing and batch processing.
Cost Model Evolution
In the security data lake model, the cost basis is quite different because of its decoupled nature. Users are typically charged based on the compute resources used to process data either in batch or in real-time. Hence, credit-based models are highly popular, while platforms may package separately for data storage and transformation. Keep this in mind in making the transition, since SIEMs historically charged on data ingestion because cost was linear to loading/indexing.
Additional Reading
While the topic of data architectures is quite vast, the links below provide an additional primer of the basics of modern, high-scale data analytics pipelines:
This article by Ross Haleliuk covers security vendors that apply these types of architectures.
Due to the size of security logs in modern organizations, a need has emerged to provide interoperability for query engines to avoid transfer costs. In that same vein, security teams are also opting for unified rule logic and less vendor lock-in. Let’s discuss interoperability and the technology that’s powering these trends.
Storage, Table, and Log Formats
Although a data lake architecture is a strong foundation for scale, it’s not guaranteed by default. There are several components worth understanding that can significantly optimize query times and reduce overhead costs. Additionally, the push for interoperability has led to increased innovation and compatibility for querying across multiple datasets. Let’s quickly cover columnar storage formats like ORC and Parquet and open table formats like Iceberg, Hudi, and Delta.
Column-based Storage
A virtuous side-effect of product innovation is the supporting technology that comes with it. As Silicon Valley hyperscale companies exploded, so did their underlying data needs. Hence, a large list of technologies were born as part of the Hadoop ecosystem for distributed data processing, and column-based data formats are a notable mention.
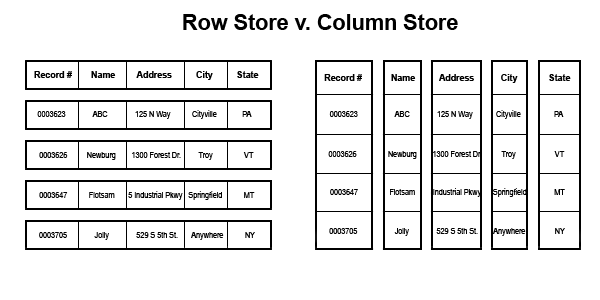
With column-based storage formats, data can be queried by loading a particular column into memory instead of the entire row. This has the benefits of improved query performance and a lower cost of scanning data. However, as mentioned above in the IP threat hunting example, you need to know the residing column containing your data, so a generic string search across the entire row does not natively work.
When it comes to implementing column-based storage, the standard formats are Apache’s Parquet and ORC. I won’t dive into the nuance between these, this AWS article briefly covers it. The visual below demonstrates the efficiencies of querying across a particular query versus the need to load an entire row.
(From Scaling Redshift without Scaling Costs by Giphy Engineering)
Storage Metadata
While storage formats are the foundation for data at rest, the metadata layer provides the query engine instructions on where to look to resolve queries and understand schemas. The industry is quickly aligning towards open metadata table formats in a push for higher data portability and avoiding lock-in.
In the old world, data lakes or monolithic systems, you would use a native loader and then pay the vendor’s storage cost, but with open formats, you use commodity storage, and the metadata is managed in an open format that can be idealistically loaded from other query engines. Three popular formats today are Apache Iceberg, Apache Hudi, and Delta, each of which originated inside Netflix, Databricks, and Uber, respectively, and each of which is open source on GitHub via the Apache or Linux foundations.
Each table format is designed to make data engineering simpler by supporting schema evolution (when fields are modified in a table), time travel (data snapshots in tables), open metadata (data about the data to aid in querying), and more. These added features improve data reliability.
The ideal outcome of opting into an open table format is that query engines can be swapped or intermingled for different use cases, such as machine learning or query optimizations. A potential tradeoff when using open table formats, however, is that performance may not be as optimized as if it were natively loaded into that particular platform’s proprietary format, although vendors are working to change that.
Unified Security Log Schemas
Finally, in the theme of openness, the security community is embracing open-source log standards to solve data normalization challenges across log sources. Two popular open-source projects, OCSF (by Splunk, AWS, and others) and ECS (created by Elastic) exist to make detection and response simpler by aligning all incoming log data to a singular normalized schema. While this has the benefit of rules and searches becoming uniform and enabling portability of security logic between platforms, it could have performance downsides in highly-nested cases. However, it does directly address threat hunting across log sources as long as there’s a clean mapping from the originating data. Solutions like Security Lake are pushing these formats, too.
Now that we have covered the basics let’s step through the big data query engines that exist today to take advantage of these architectures.
Cloud Platform Data Lakes
Cloud-native data lakes typically reside close to the originating data sources, enabling simplicity and less transfer costs. These offerings are typically only one piece of a larger product catalog, which makes creating an end-to-end solution a design, engineering, and configuration exercise.
AWS Ecosystem
As of Q2 2023, Amazon remains the market leader in the cloud1, and as a result, most security teams have security-relevant data sitting in S3.
Amazon S3 remains the most common AWS destination for security-relevant logs like CloudTrail and S3 Server Access Logs due to its low-cost flexibility, extreme scalability, and ease of use. As all detection engineers know, centralizing and normalization across logs is a significant pain, and hence, Amazon has taken it upon itself to make that easier. The concept of Security Lake is that logs generated from internal services (and partners) are normalized into the OCSF format and stored in Parquet in S3, effectively bootstrapping your data lake. Tables are managed in Glue and data is queryable via Lakeformation and Athena. The idea is that AWS will build a partner ecosystem to hydrate the Security Lake with additional logs and include a robust set of subscribers to enable security businesses to achieve analysis and other processing on that data.
The AWS Security Lake ecosystem interfaces with AWS Athena to search data by default, but their goal is to take an overall agnostic approach when it comes to data processing. AWS Athena uses AWS Glue for its metadata catalog while also supporting Iceberg as an open table format. OpenSearch also remains an option for full-text search and features like dashboarding, but does not natively play into the interoperability of data lakes. However, the idea of a data lake alongside an engine like OpenSearch could work in harmony to address multiple personas in a security team.
AWS also offers other real-time streaming analytics and data warehousing solutions for use in rules analysis, machine learning, or other analytics. Namely, EMR (Spark), Kinesis, and Redshift. Due to the high nuance and complexity of EMR, most security teams should probably not use it directly and instead interface with a simpler service like Kinesis or Athena to accomplish similar use cases. Kinesis can be used for instrumenting real-time analysis pipelines and windowing, and Redshift can be used as a classic data warehouse over vast amounts of data.
GCP and Azure
GCP and Azure provide underlying products for SIEM that may or may not be based on a data lake. I won’t mention them here. If you are interested, you can read about Chronicle and Sentinel, respectively. If you live predominately in the Google ecosystem, BigQuery is an excellent choice for a serverless data warehouse. This offering is similar to Athena.
Commercial Warehouse Offerings
On the commercial side, two platforms stand out for security data - Snowflake and Databricks. As opposed to the cloud data platforms, these companies are dedicated to solving the data analytics problem while remaining cloud agnostic. They offer a range of pipeline and query engine features, are creating a robust partner ecosystem, and are evolving quickly, especially in the age of training and deploying AI models.
Snowflake started as a cloud data warehouse and has embraced the separation of storage and compute to drive extremely high-performance searches. More recently, Snowflake introduced Snowpark (Snowpark) for in-stream real-time processing (with Python support), native Apache Iceberg support for interoperability, and has acquired companies like Streamlit for visualization frameworks.
Databricks was founded by the co-founders of Apache Spark and has led the charge in productionizing data pipelines, AI/ML, and high-scale data analytics. These workloads are more traditionally based on Spark with a heavy emphasis on data engineering, but they are now offering more straightforward SaaS offerings. Databricks aligns on Delta Lake for its open table format while also including compatability for Iceberg.
Open Source OLAP Databases
Finally, several pure open source offerings exist if you prefer full control over the processing layer. These offer extremely high-performance engines but with the operational cost of running and scaling open source software. Popular options here are Clickhouse and DuckDB, both with free and hosted options, backed by startups. These technologies are also embracing open formats like Iceberg.
Tying Everything Together
Whew. That was a lot! Let’s bring it back to security to wrap this post up. There are many ways to build on data lake architectures to support your security monitoring and SIEM needs. Perhaps you are making a decision to purchase or to build your own. Regardless, understanding these underlying pieces helps with setting the right expectations around performance, cost, and usability.
When making this transition to a data lake, you will need:
A way to centralize and normalize all the data
A mechanism to analyze and correlate structured logs
A way to threat hunt over historical data
As you build your strategy, the technologies above can influence where you perform each of those. Your team’s skillsets will also play a part in this decision, whereas if you have a highly technical team, a full data lake with no indexing could work. Whereas, with analysts, you’ll want to opt for a hybrid approach where you pick and choose which logs go to which datastore. This, of course, presents new problems around unifying searches, but it best caters to your security program.
With both architectural options, there are tradeoffs between ease of use and scale, but is that gap being closed slowly? Maybe it will correct the typical side effect of running more than one SIEM to accommodate high-value/recent logs and high-scale logs.
The best solution is one that fits your cloud stack, requirements, technical expertise, scale, budget, and level of desired effort. Typically, leaders will choose platforms that require the least amount of data movement to save on cost while improving privacy and security. Choosing tools near your stack will also decrease the time to learn new technologies and likely make purchasing more straightforward, too.
We have arrived at this inflection point where monolithic SIEMs can not accommodate the continuous scale of the cloud and security teams are forced to make trade-offs regarding what data they choose to ingest, where they may lose visibility of security incidents simply because they can’t ingest the high volume of logs. This puts security teams in a precarious position in the event of an incident, but applying the technology above makes huge steps forward in our ability to keep our company’s safer.
Thank you for reading!
https://www.statista.com/chart/18819/worldwide-market-share-of-leading-cloud-infrastructure-service-providers/