


Zero False Positives from your SIEM
Is it possible?

The downfall of SIEMs are high volumes of false positive alerts, which waste time, reduce trust, and teach your team to ignore them altogether.
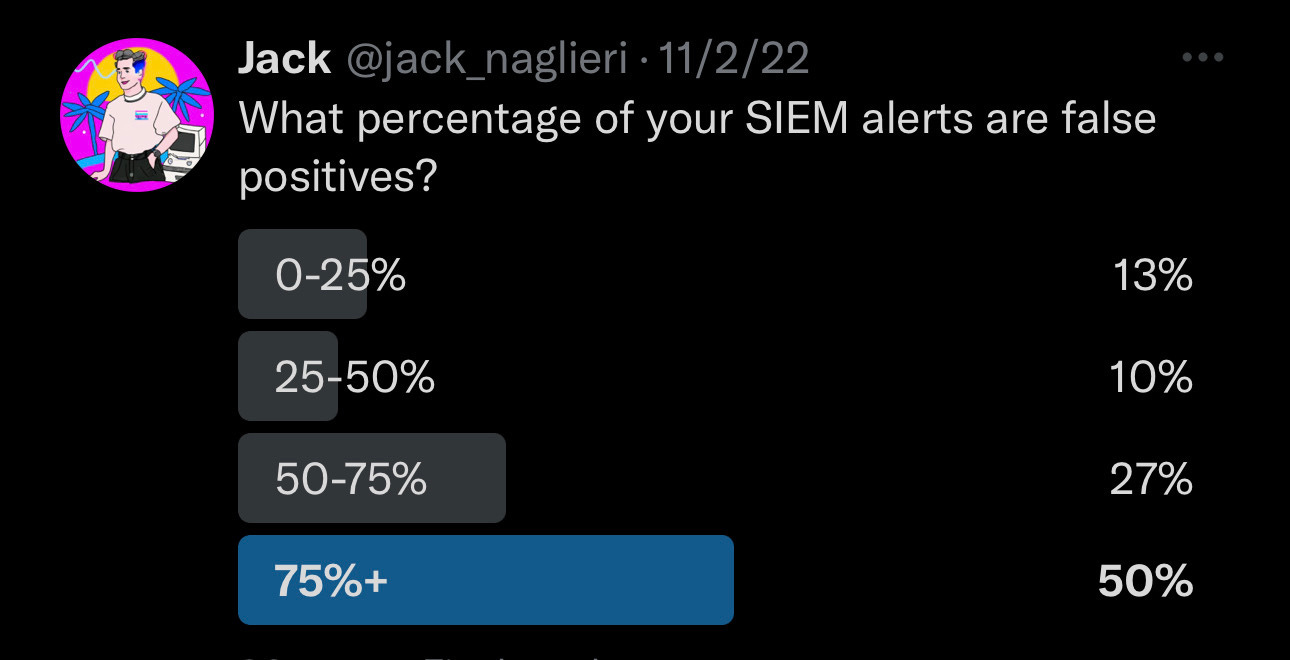
False positives result in missing the signs of an actual attack and this has unfortunately been the status quo for a long time.
Let’s discuss techniques to drive false positives down and keep them down.
False Positives = Poor Signal
From Wikipedia:
A false positive is an error in which a result incorrectly indicates the presence of a condition, while a false negative is the opposite error, where the result incorrectly indicates the absence of a condition when it is actually present.
In security monitoring, a false positive refers to an alert from your SIEM that turned out to be safe or legitimate behavior. It's a scenario we are all too familiar with. A typical false positive could look like this:
"Network traffic from [prod-01.us-east-2] identified on [port 443] to a known malicious domain [example.bad-domain[.]xyz]"
Or
"User [root] created a new cron containing the `wget` command on [prod-02.us-east-1]."
Although these may lead to helpful and proactive signal like flagging potential C2 traffic or persistence, we often find alerts like this to be misinformed somehow. The network traffic may be ephemeral and in the wrong direction, and the user adding the scheduled job may need it for legitimate reasons.
Categories of Alerts
Alerts can be grouped into three action-oriented categories:
Informational that requires no action
Potentially bad to be investigated
Obviously bad that leads to an incident
“Informational” is typically used during active response or compliance evidence collection. The purpose is to siphon common and legitimate behaviors, such as successful SSH logins or 2FA authentication, to the side. It’s hugely valuable to have fast access to these logs instead of combing over the entire dataset, which could take hours or may not even be possible, depending on your data retention. These alerts should not page a human, they should just happen in the background.
“Potentially bad” is a medium-confidence alert that could be part of a larger attack pattern which should be investigated by a human. This is where most false positives live, and this is the biggest area for improvement. One could even argue these should not exist at all. Alerts in this category are often too subjective based on what “bad” means to that particular organization.
Finally, “obviously bad” alerts are behaviors that should never occur. This includes patterns from past attacks or high-confidence indicators provided by a trusted or internal source. Examples of this include:
Monitoring atomic indicators (this-malware[.]domain) combined with a kill-chain component (command-and-control)
System commands executed that result in a loss of confidentiality or system integrity (wget issued from a production system to an unknown, external domain)
Each alert type can produce false positives, so let’s step through strategies to reduce them.
Set a True Positive Goal
Before you begin tuning, it’s important to define your desired percentage of true positives (I like to think glass-half-full).
Let’s say the goal rate is 80% (very good). Now, take an inventory of your current alert rate by dividing the total number of true positives by the total number of alerts within a given period. To get more granular, do this rule-by-rule.
This provides a goal to work towards and may even flag immediate rules to address or disable.
Rapid7 wrote a great blog post on calculating Rule Efficacy based on the basic formula above but goes into greater detail on monitoring analyst time and the opportunity cost of creating new rules.
With this, let’s find opportunities to reduce!
False Positive Examples
Addressing common false positive alerts.
Invalid rules
Basic errors in rule logic (== vs. !=) or too broad of a rule (all GetObject events with the word `cc` in them) can generate thousands of accidental alerts that do not accurately represent the initial and desired outcome of that rule.
Traveling users with legitimate logins
If you monitor for suspicious logins to your IdP (e.g. not from your country of residence), a typical false positive scenario could be:
“Jack, someone just tried logging in with your Okta credentials from Spain, are you currently there right now?”
“No. I’m in San Francisco.”
Unless you can physically track my whereabouts 👀, this rule can be low fidelity.
One-time behaviors in production
Privileged users may occasionally perform one-off commands on systems during outages or to test certain behaviors. This can result in a very scary alert that ultimately was fine.
Outdated intelligence or missing context
This can occur because your reference data used in analysis, such as user-to-organization mapping, is outdated or missing altogether.
Ways to Prevent False Positives
Delete ineffective or irrelevant rules
Removing rules can make your program more focused and result in higher signal and value.
Are you prioritizing the most important systems to monitor? Or are you writing rules to get more MITRE coverage? We want to make sure as new rules are created that we don’t sacrifice fidelity.
Automated user confirmation
Confirm the flagged behavior first by pinging the offending user on Slack (or Teams?) before notifying the security team.
This is very common in consumer identity systems where users are sent a 6-digit code over SMS (ugh) or use an authentication application (better) or security key (best) as a second factor when the browser or device is not trusted.
This pattern can also be reused in security monitoring with a little bit of automation. It applies across many scenarios where a human inside your organization performs a specific action. Bonus points if you can confirm their identity using a second factor (not SMS).
In-depth rule testing before deployment
Quality is not an act, it is a habit. ― Aristotle
What a relevant quote about security rules. Aristotle was ahead of his time.
You must always test your rules before deploying to production. There are many ways to do it, some of which involve sample data, backtested data, and more. Luckily, I wrote an entire post for you to learn about rule testing! Check it out here:
Refine your rule logic
When we analyze log data, we take the total set of logs and continually reduce it further and further until we’re left with the set of logs that express the behaviors we want to see.
Refine your rule logic by adding conditions such as:
Specific event actions
Static allow or deny lists (users, machines, IP space, etc.)
Examining request/response parameters
Filtering the environment/region analyzed (production only)
Along with examining other fields in the log.
Correlate behaviors across time and space
Correlating multiple behaviors together is an effective way to increase confidence and express more complex TTPs.
For example, successive failed logins, followed by one successful login, followed by creating a user. This could reveal persistence.
Correlating involves multiple datasets analyzed historically but can add additional dimensions to your alerts that increase confidence.
External enrichment
Context is king with monitoring.
To understand that Jack is a CEO, and it’s atypical for him to log into Production, you need an enrichment from a dynamic lookup table. These can be achieved by periodically syncing data from an HR system and then enriching your log data. This business-level context can greatly reduce your false positive rate.
Similarly, another form of external enrichment is Threat Intelligence. You should rarely use Threat Intelligence as a primary mechanism for alerting, however. It’s highly false positive-prone because atomic indicators are too dynamic. The best way to use it is in conjunction with other behaviors (user “x” performed action “y") as a way of increasing confidence. There are exceptions here, obviously, such as previously observed or ongoing indicators in an attack.
Start slow and gradually ramp
As defenders, effective and proactive detection involves pragmatic collection, analysis, and correlation in log data. Start with what matters the most, have a high bar for fidelity, and only augment with discipline to cover your threat model.
There is no foolproof way to “find the breach,” but many tools are at our disposal to increase our confidence and abilities. Practice monitoring in-depth, use the techniques I described above to pare down your alerts, and be extra vigilent about what you ask a human to do!