


The Anatomy of a High Quality SIEM Rule
A framework for building detections that cut through noise and accelerate incident response.

Welcome to Detection at Scale, a newsletter for SecOps practitioners covering detection engineering, SIEM technology, and the latest breaches and vulnerabilities. We are back after Hacker Summer Camp and an exciting product announcement!
Every security analyst dreams of a perfectly accurate alert that exposes attackers before harm is done, consistently with crystal-clear next steps. While this might be rare in reality, shouldn't we aim high?
This blog post introduces a simple framework for writing rules focusing on high-confidence behaviors, specific attacker techniques, and clearly defined next steps for your analyst colleagues. By following these rules, we can significantly improve the quality, actionability, and overall focus of our alerts.
Track High-Confidence Behaviors
Rules should strike a balance between confidence and impact.
How confident are we in this rule's ability to detect the modeled behavior? How much damage could occur if this actually happened? In the continuous stream of security signals, these two variables can help defenders prioritize and reduce the potential for the lower left quadrant.

Defining a rule with high confidence means the necessary context exists in logs or lookups to understand the behavior.
Similar to a vague ChatGPT prompt, your rule's effectiveness is determined by the specificity of the request: "Is it bad if someone logs in at 15:00 UTC?" versus "Is it bad if someone logged into a production system during non-working hours from a non-managed asset?" Our rules should follow a similar level of detail—this increases confidence in our alerts.
There is also a relationship between confidence and impact regarding the urgency of your response. Although we may have high confidence, it doesn’t always warrant a war-room situation. The low-impact, high-confidence alerts can help confirm the system works. Maybe these go straight to automation and are never touched by a human. The balance is vital.
A healthy security monitoring program should come with a range of alert severities, not just the ones in the upper right quadrant. You can work in SecOps for years and never experience an incident warranting that level of response!
Here are a few examples of high-confidence alerts:
Crypto mining software was successfully installed on a production host from a non-service account.
A user logged into a production host from an exact IoC match from a previous incident.
An admin disabled 2FA for their user account on your IdP and did not re-enable it within 30 minutes.
Most of these rules correlate multiple contexts together, which is crucial for staying on the right side of our quadrant. If a behavior is observed (like disabling a CloudTrail) without specifying the context (in a particular group of accounts), then you'll get alerts for developers... developing. This turns into untuned noise.
How can you improve confidence in your rules? Add more elements to correlate against and test the rules well. Use an enrichment to understand who is making the request, filter out the non-production environments, and use sequential detection for more accurate monitoring of techniques.
Monitor Relevant Tactics and Techniques
Rules that represent vague behaviors decrease confidence and reliability in alerting.
Rules should exist to detect a particular stage and technique of an attack. Is this behavior actually malicious? Should it be logged for compliance purposes? Often, that line is blurred.
As a refresher from our friends at MITRE on tactics and techniques:
Tactics represent the "why" of an ATT&CK technique. It is the adversary's tactical goal: the reason for performing an action. For example, an adversary may want to achieve credential access.
Only enable rules relevant to your threat models and risk appetite. Most default SIEM rules were not designed with your people, technology, and processes in mind and need an additional intelligence layer to yield returns.

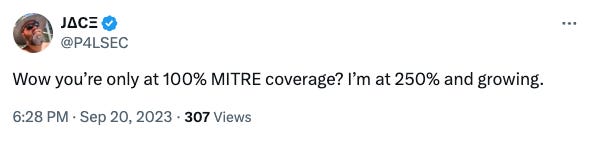
And... aiming for "100% coverage" is meaningless, as confirmed by MITRE:
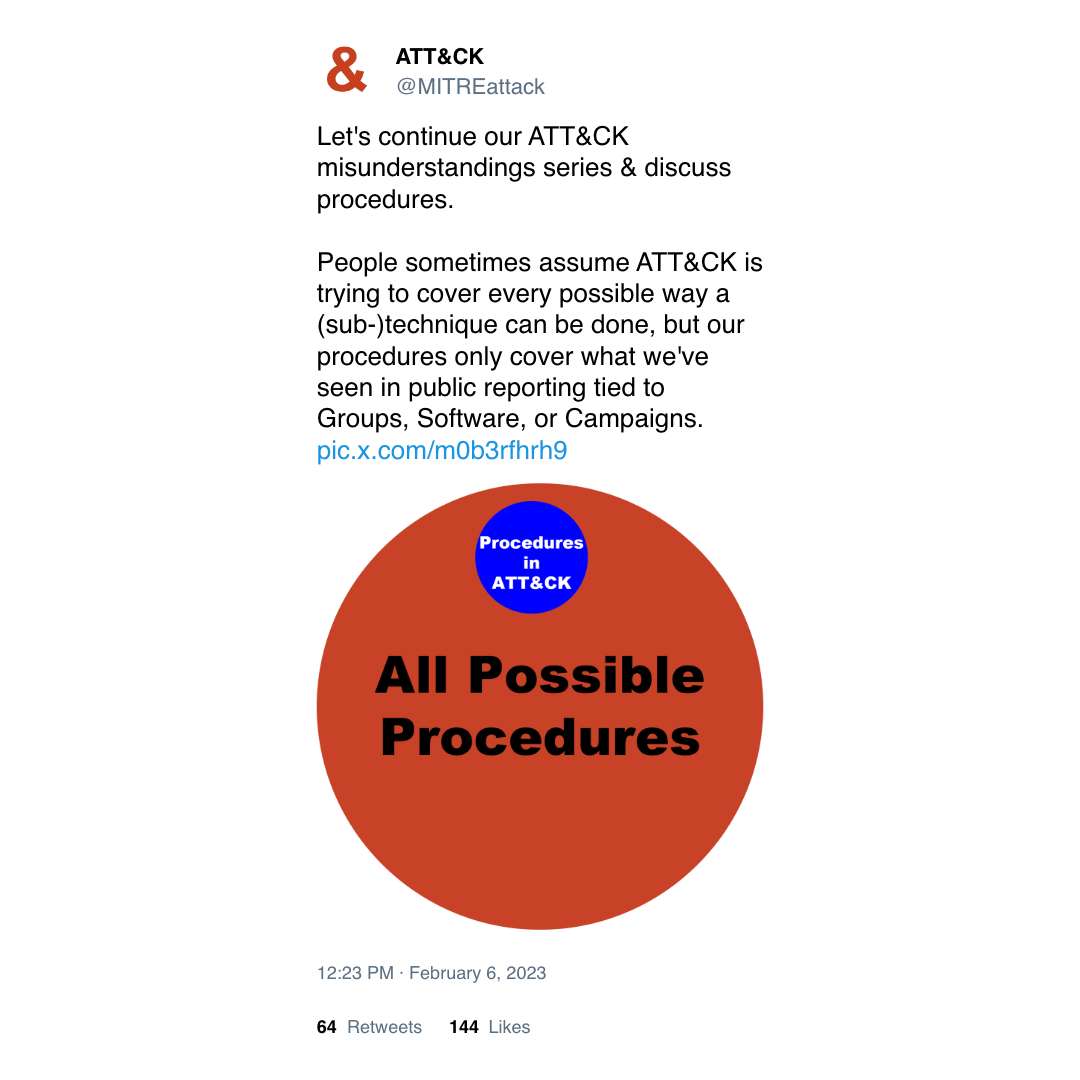
Researching and developing unique rules based on the data in your SIEM fills in the visibility gaps and creates complementary signals to the generic rules out there already.
Most important is having rules that reflect how your people, processes, and technology work together.
Test your controls and monitoring often. When you find gaps, iterate, add more logging and auditing, and repeat.
I'll repeat that "100% coverage" is nonsense and not a gauge of success.
Define Clear Triage Steps
If alerts have no clear path to resolution, they should simply log activity versus paging a human.
Building out alert-specific runbooks helps illuminate other response-related blindspots. For example, if the runbook for an alert requires checking a human's prior login history for the past year, you need to ensure that history exists!
When there is a clear step to resolve, it saves time and effort that may otherwise be wasted by a vague alert with no intention.
Clearly defined next steps also identify hotspots for automation! If you find yourself writing the same runbook step, it's time to throw a little automation or AI magic in the mix (kidding... or am I?). It can be very common to just ask (read: nicely interrogate) users if they did something1.
Most SIEMs declare a list of potential false positives in defining the next steps. I personally have never understood the utility of calling out a false positive without stopping it in the logic itself. This would violate the first rule of the framework: high-confidence alerts!
In short, your rules should clearly indicate a path to resolution. This will improve preparedness and reduce the time it takes to resolve.
Bringing the Three Parts Together
In conclusion, crafting high-quality security rules is both an art and a science. Focusing on high-confidence behaviors, relevant tactics and techniques, and clearly defined next steps can significantly enhance our security posture and reduce alert fatigue.
Remember:
Strive for high-confidence rules that balance specificity with actionability. Use data to reinforce confidence and adjust accordingly.
Align your rules with tactics and techniques pertinent to your organization's threat model.
Develop clear, actionable next steps for each alert, paving the way for efficient response and potential automation.
By implementing this framework, security teams can move away from the "alert overload" paradigm and towards a more focused, practical approach to threat detection and response. It's not about having the most rules or achieving mythical "100% coverage" – it's about having the proper rules that provide meaningful, actionable insights into your security landscape.
As you refine your rule-writing process, remember it's an iterative journey. Test, refine, and adapt your rules based on your evolving threat landscape and organizational needs. By doing so, you'll improve your security posture and empower your analysts to respond more effectively to genuine threats.
Ultimately, the goal is not just to detect threats but to do so with precision, confidence, and a clear path to resolution. That's the true measure of a high-quality security rule!
https://github.com/openai/openai-security-bots